Understanding FixRes - Fixing the train-test resolution discrepancy
Introduction
In this blog post we will try to understand the ideas introduced in the FixRes paper published by the Facebook AI Research team.
We will implement the method described in the paper while training a ResNet-50 model from scratch in PyTorch, on the Cassava leaf disease classification dataset from Kaggle.
Finally, we will see how we can use this method in fast.ai with transfer learning.
The train-test resolution discrepancy
The paper shows that existing data augmentation techniques introduces a significant difference in sizes of objects that a CNN sees during training and testing.
During training, it is common to extract/crop a random region of classification from an image and then resize it to a resolution that is compatible with the CNN architecture.
For example, the crop would be resized to 224 x 224 when using AlexNet. However, some architectures like ResNet don't have such a requirement. Even in this case, all images within a batch need to be resized to a common resolution.
This kind of augmentation is what we get with RandomResizedCrop in PyTorch.
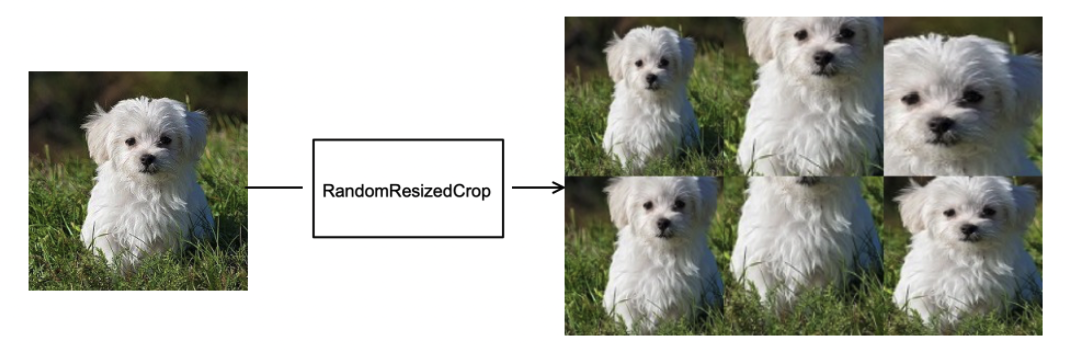
(Source) RandomResizedCrop randomly selects different areas in the input image and resizes them to the same size.
During testing, however, we just extract a center crop of the size we would like to feed to the model.
The result of this difference during training and testing is this:

This image shows that although we are providing the same resolution of images to the model during training and testing, the scale of horses that the model sees during these phases is different.
This is because the nature of preprocessing used tends to zoom on objects, resulting in a larger horse during training compared to testing.
This is a problem because convolutional neural networks do not have "built-in scale invariance", i.e. they are sensitive to the sizes of objects in the images used to train them.
Fixing the apparent object size problem
To fix this discrepancy in the apparent size of objects during training and testing, the authors propose two options:
- Decrease the resolution of images during training.
- Increase the resolution of images during testing.
As a result, the model will see horses of the same size.
The authors found that the ratio of the size of objects seen at test time to size of objects seen at train time lies between between 0.28 and 1.
This means that during test time, some objects may appear to be just a third of their size during training time!
With standard pre-processing, the authors claim that objects at test time are on average 0.8 times what they appear at training time.
This means that if we choose to decrease the resolution of images during training, we need to make it 0.8 times the resolution we use during training.
If we choose to increase the resolution of images during testing instead, then we need to make them
For example, if we have images of resolution 224 x 224, we could adjust the resolution in one of the following ways:
| Method | Resolution at training time | Resolution at test time |
|---|---|---|
| Decrease resolution at training time | ||
| Increase resolution at training time |
Table 1: Adjusted training and test resolutions for images of size 224x224
Wouldn't life be so wonderful if everything "just worked" when we did this?
Unfortunately, the authors discovered that changing the resolution of images during testing significantly skews the distribution of activations in the model.
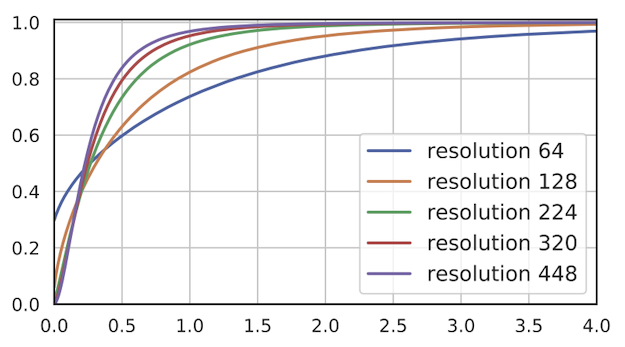
This graph shows the cumulative density of activations after average pooling layer for a ResNet-50 trained at a resolution of 224 and tested at the different resolutions shown.
As we can see, lower resolutions result in more activations being 0 and activations are more spread out. At higher resolutions, we see the opposite - the number of 0 activations drops and the activations are less spread out.
If the distribution of activations significantly change at test time, their values will not be in the range that the final classifier was trained for. As a result, the accuracy of the model will suffer.
Fixing the skewed activation statistics
When the distributions of activations change as described in the previous section, the last few layers of the network are affected most.
The earlier layers of a convolutional neural network that consist of convolutions, activations and other similar layers remain largely unaffected.
The authors mention two ways to deal with these skewed activations:
- Parametric adaptation
- Fine-tuning
The authors mention that parametric adaptation provided a measurable but limited improvement in accuracy. Therefore, we'll focus on how to fine-tune the model instead.
A change in resolution of images at test time is effectively a domain shift, and a common way to deal with domain shift is fine-tuning the model.
When fine-tuning the model we use the same images from the training set but with a higher resolution.
The authors also mention that we need to fine-tune the last few layers of the model which includes any batch normalization layer that precedes the pooling layer.
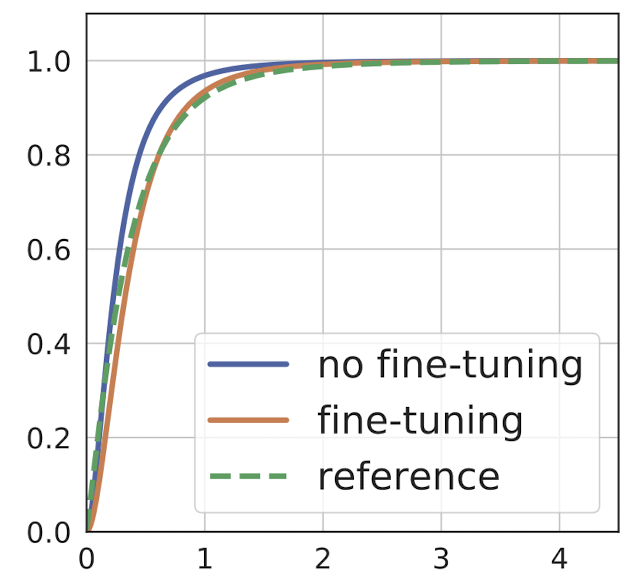
The dotted green line in the image shows the distribution of activations when using the same resolution of images for training and testing.
The blue line shows the distribution when we use larger images for testing without fine tuning the last batch normalization layer.
The orange line shows the distrbution after the last batch normalization layer has been fine-tuned. It shows a distribution that is almost identical to the dotted green line.
Training a model using PyTorch
We will now test the effectiveness of this method using the Cassava leaf disease classification dataset from Kaggle.
We will first train a baseline model and then compare its performance with another one we train using the FixRes method.
Baseline model
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms, models
from torch.utils.data import Dataset, DataLoader
from torch.optim import lr_scheduler
from PIL import Image
import copy
import os
import time
# Ignore warnings to keep the output nice and pretty
import warnings
warnings.filterwarnings("ignore")The train-test split being used was created in a Fastbook reading group and can be found here.
df = pd.read_csv('../wandb_cassava_train_val_split.csv')
df.head()| image_id | label | is_val | |
|---|---|---|---|
| 0 | 1000015157.jpg | 0 | False |
| 1 | 1000201771.jpg | 3 | False |
| 2 | 100042118.jpg | 1 | False |
| 3 | 1000723321.jpg | 1 | False |
| 4 | 1000812911.jpg | 3 | False |
We first create a Dataset for the data.
class CassavaDataset(Dataset):
def __init__(self, df, root_dir, transform=None):
self.df = df
self.root_dir = root_dir
self.transform=transform
def __len__(self):
return len(self.df)
def __getitem__(self, idx):
if torch.is_tensor(idx):
idx = idx.tolist()
# We get the path of the image
img_path = os.path.join(self.root_dir, self.df.iloc[idx, 0])
# We load the image and label
image = Image.open(img_path)
label = self.df.iloc[idx, 1]
# We create a single "sample" with the image and its label
sample = {"image": image, "label": label}
# We apply transforms if specified
if self.transform:
sample["image"] = self.transform(sample["image"])
return sampleWe then define the augmentation we'll use during training and testing.
As you can see, we use RandomResizedCrop during training and CenterCrop during testing with the same size.
data_transforms = {
'train': transforms.Compose([
# RandomResizedCrop of size 224 used during training
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
]),
'val': transforms.Compose([
# CenterCrop of size 224 used during testing
transforms.CenterCrop(224),
transforms.ToTensor(),
]),
}We can now create training and validation datasets.
def get_datasets(data_transforms):
# We create a training dataset using rows in our data file that have `is_val` equal to False
# using the transforms we have created above for training...
train_ds = CassavaDataset(df[df.is_val == False].reset_index(drop=True), '../train_images', data_transforms['train'])
# ... and a test dataset with rows that have `is_val` equal to True,
# using the transforms we have created above for testing.
val_ds = CassavaDataset(df[df.is_val == True].reset_index(drop=True), '../train_images', data_transforms['val'])
return {
"train": train_ds,
"val": val_ds
}
datasets = get_datasets(data_transforms)
dataset_sizes = {x: len(datasets[x]) for x in ['train', 'val']}The next step is to create data loaders for these datasets.
def get_dataloaders(datasets, bs=64):
# We create dataloaders from the datasets to enable retrieval of data in batches,
# to shuffle the data at every epoch, and to parallelize data retrieval (using 4 workers in this case)
return {
"train": DataLoader(datasets["train"], batch_size=bs, shuffle=True, num_workers=4),
"val": DataLoader(datasets["val"], batch_size=bs, shuffle=True, num_workers=4)
}
dataloaders = get_dataloaders(datasets)We now create three utility methods:
train_loopto train the model for one epocheval_loopto evaluate the model on validation data for one epochtrainto calltrain_loopandeval_loopfor the number of epochs specified, and also to keep track of the best model weights.
def train_loop(model, dataloader, criterion, optimizer, ds_size, fine_tune):
# We will use the `fine_tune` parameter to ensure that we are
# modifying only the last batch normalization layer.
if fine_tune:
model.eval()
model.layer4[2].bn3.train()
# Otherwise, we put the model in `train` mode
# so that all batch normalization layers are updated
else:
model.train()
# We keep a track of the loss over all batches in an epoch
# to later calculate the average loss...
running_loss = 0.0
# ... and we also keep track of how many correct predictions the
# model makes to later calculate the average accuracy.
running_corrects = 0
# We then loop through every batch in an epoch
for sample in dataloader:
# Extract the images...
inputs = sample["image"].to(device)
# ... and their corresponding labels
labels = sample["label"].to(device)
# Boilerplate PyTorch training code:
# 1. Reset all gradients through optimizer
optimizer.zero_grad()
# 2. Feed model inputs and capture outputs
outputs = model(inputs)
# 3. Calculate class predicted by model
_, preds = torch.max(outputs, 1)
# 4. Use correct `labels` and model `outputs` to calculate loss
loss = criterion(outputs, labels)
# 5. Compute gradients using the calculated loss
loss.backward()
# 6. Use optimizer to update model parameters
optimizer.step()
# Update variables keeping track of loss and correct predictions
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
# Calculate the average loss and average accuracy for the epoch
epoch_loss = running_loss / ds_size
epoch_acc = running_corrects.double() / ds_size
return epoch_loss, epoch_acc
def eval_loop(model, dataloader, criterion, ds_size):
# We put the model in evaluation mode
model.eval()
running_loss = 0.0
running_corrects = 0
# The code used in the evaluation loop is very similar to that used
# in the training loop.
# The only difference is we use `torch.no_grad()` to ensure we
# don't compute any gradients while in evaluation mode.
with torch.no_grad():
for sample in dataloader:
inputs = sample["image"].to(device)
labels = sample["label"].to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / ds_size
epoch_acc = running_corrects.double() / ds_size
return epoch_loss, epoch_acc
def train(
model, train_loader, val_loader,
epochs, criterion, optimizer,
fine_tune=False
):
train_start = time.time()
# We save the model weights that give the best accuracy
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(epochs):
epoch_start = time.time()
# We run the training loop...
train_loss, train_acc = train_loop(
model, train_loader, criterion,
optimizer, dataset_sizes["train"],
fine_tune=fine_tune
)
# ... and then the validation loop...
val_loss, val_acc = eval_loop(
model, val_loader, criterion, dataset_sizes["val"]
)
# ... and save the model if it has the best validation accuracy so far
if val_acc > best_acc:
best_acc = val_acc
best_model_wts = copy.deepcopy(model.state_dict())
time_elapsed = time.time() - epoch_start
print(f'Epoch: {epoch+1:02} | Epoch Time: {time_elapsed // 60:.0f}m {time_elapsed % 60:.0f}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train Acc: {train_acc*100:.2f}%')
print(f'\t Val. Loss: {val_loss:.3f} | Val. Acc: {val_acc*100:.2f}%')
time_elapsed = time.time() - train_start
print()
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# Load the weights that gave the best accuracy
model.load_state_dict(best_model_wts)
return modelWe create an instance of a resnet50 model that we will use.
model = models.resnet50()Since ResNet-50 is trained in ImageNet, it has 1000 outputs.
We need to modify the fully connected layer so that the number of ouputs equals the number of classes we have in our dataset.
# Keep the same number of inputs,
# but change the number of outputs to the number of unique labels in our dataset
model.fc = nn.Linear(model.fc.in_features, df.label.unique().size)# Use the power of the GPU! 💪
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = model.to(device)We now train the model for 10 epochs using the AdamW optimizer with default parameters.
N_EPOCHS=10
criterion = nn.CrossEntropyLoss()
optimizer = optim.AdamW(model.parameters(), weight_decay=0.1)
model = train(model, dataloaders["train"], dataloaders["val"], N_EPOCHS, criterion, optimizer)Epoch: 01 | Epoch Time: 3m 1s
Train Loss: 1.105 | Train Acc: 62.14%
Val. Loss: 1.139 | Val. Acc: 61.58%
Epoch: 02 | Epoch Time: 3m 8s
Train Loss: 0.928 | Train Acc: 64.79%
Val. Loss: 1.594 | Val. Acc: 23.35%
Epoch: 03 | Epoch Time: 3m 8s
Train Loss: 0.873 | Train Acc: 67.02%
Val. Loss: 2.089 | Val. Acc: 13.58%
Epoch: 04 | Epoch Time: 3m 8s
Train Loss: 0.819 | Train Acc: 68.94%
Val. Loss: 1.667 | Val. Acc: 33.68%
Epoch: 05 | Epoch Time: 3m 12s
Train Loss: 0.776 | Train Acc: 70.80%
Val. Loss: 1.022 | Val. Acc: 64.71%
Epoch: 06 | Epoch Time: 3m 8s
Train Loss: 0.757 | Train Acc: 71.75%
Val. Loss: 1.000 | Val. Acc: 64.95%
Epoch: 07 | Epoch Time: 3m 8s
Train Loss: 0.736 | Train Acc: 72.81%
Val. Loss: 1.207 | Val. Acc: 63.29%
Epoch: 08 | Epoch Time: 3m 8s
Train Loss: 0.710 | Train Acc: 73.63%
Val. Loss: 1.155 | Val. Acc: 51.16%
Epoch: 09 | Epoch Time: 3m 8s
Train Loss: 0.702 | Train Acc: 74.31%
Val. Loss: 0.926 | Val. Acc: 66.77%
Epoch: 10 | Epoch Time: 3m 8s
Train Loss: 0.682 | Train Acc: 75.02%
Val. Loss: 0.786 | Val. Acc: 71.09%
Training complete in 31m 17s
Best val Acc: 0.710914
The baseline model has an accuracy of 71.09%.
Higher resolution images during testing
The first way to use FixRes is by increasing the resolution of images at test time.
test_sizes = [64, 128, 224, 384, 480]
accuracy = []
for size in test_sizes:
# For each of the test_sizes we
# 1. First resize the image to 1.25 the size we want during testing
# 2. Take a CenterCrop of the desired size for testing
trans = transforms.Compose([
transforms.Resize(int(1.25 * size)),
transforms.CenterCrop(size),
transforms.ToTensor(),
])
# We create a new dataset and dataloader with these transforms...
val_ds = CassavaDataset(df[df.is_val == True].reset_index(drop=True), '../train_images', trans)
ds_size = len(val_ds)
dataloader = DataLoader(val_ds, batch_size=64, shuffle=True, num_workers=4)
# ... and calculate the model's accuracy
loss, acc = eval_loop(model, dataloader, criterion, ds_size)
accuracy.append(acc.item())We can then plot the different test sizes against the accuracy of the model to understand how the resolution of images at test time affects model accuracy.
import matplotlib.pyplot as plt
max_acc = max(accuracy)
max_res = test_sizes[accuracy.index(max_acc)]
plt.plot(test_sizes, accuracy)
plt.scatter(224, 0.7109)
plt.scatter(max_res, max_acc)
plt.show()
We can see that using a larger image resolution increases the accuracy from 71.09% (the blue dot) to 77.89% at a resolution of 384 (the orange dot).
Note that using Resize (1.25 * 224) + CenterCrop (224) gives a higher accuracy than using just CenterCrop (224). This shows that the size of objects seen by the model is indeed different at test time and has an adverse effect on the accuracy.
Also note that we have obtained a better accuracy from the model without even fine-tuning the model at a larger resolution!
Let us now fine-tune the last layers of the model at a resolution of 384, since that's the resolution at which the model performed best.
# Freeze all layers apart from the fully connected layer
for name, child in model.named_children():
if 'fc' not in name:
for _, params in child.named_parameters():
params.requires_grad = False
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(384), # RandomResizedCrop of size 384 during training
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
]),
'val': transforms.Compose([
transforms.Resize(480), # First resize to 1.25 * 384 = 480
transforms.CenterCrop(384), # and then extract a CenterCrop of size 384
transforms.ToTensor(),
]),
}
datasets = get_datasets(data_transforms)
dataset_sizes = {x: len(datasets[x]) for x in ['train', 'val']}
dataloaders = get_dataloaders(datasets)
criterion = nn.CrossEntropyLoss()
optimizer = optim.AdamW(model.parameters(), weight_decay=0.1)
model = train(model, dataloaders["train"], dataloaders["val"], 5, criterion, optimizer, fine_tune=True)Epoch: 01 | Epoch Time: 3m 20s
Train Loss: 0.650 | Train Acc: 76.00%
Val. Loss: 0.582 | Val. Acc: 79.46%
Epoch: 02 | Epoch Time: 3m 22s
Train Loss: 0.642 | Train Acc: 76.78%
Val. Loss: 0.587 | Val. Acc: 79.67%
Epoch: 03 | Epoch Time: 3m 22s
Train Loss: 0.632 | Train Acc: 76.88%
Val. Loss: 0.588 | Val. Acc: 79.67%
Epoch: 04 | Epoch Time: 3m 23s
Train Loss: 0.644 | Train Acc: 76.59%
Val. Loss: 0.589 | Val. Acc: 79.53%
Epoch: 05 | Epoch Time: 3m 23s
Train Loss: 0.640 | Train Acc: 76.72%
Val. Loss: 0.585 | Val. Acc: 79.46%
Training complete in 16m 50s
Best val Acc: 0.796681
By passing fine_tune=True to the train method, we ensured that the entire model was in eval mode and just the last BatchNorm layer before the pooling layer was in train mode.
And fine-tuning was indeed helpful! It bumped the accuracy of our model from 77.89% to 79.67%!
Lower resolution images during training
We could have used images with a lower resolution during training instead of increasing the resolution of images during testing.
From the calculations in Table 1, we would use images of resolution 179x179 during training and images of resolution 224x224 during testing.
Training the model with these resolutions is left as an exercise for the reader. 👀
Transfer learning using fast.ai
The FixRes method can also be used with transfer learning. The authors mention that when fine-tuning a pre-trained model, they do the following:
- Initialize the model with pre-trained weights
- Train the entire model for several epochs at the training resolution
- Fine-tune the last BatchNorm and fully connected layer with a higher resolution
We will try this approach with fast.ai.
The code that follows was inspired by @morgymcg's experiments available on GitHub: morganmcg1/fastgarden
We will continue using the same dataset and the same train-test split described at the beginning of the PyTorch experiments.
from fastai.vision.all import *
# Define the path where the images are
path = Path('..')
# get_x fetches a single image
def get_x(row):
return path/'train_images'/row['image_id']
# get_y fetches the label of a single image
def get_y(row):
return row['label']
# The splitter returns the train/test split based on the
# `is_val` column in our CSV file.
def splitter(df):
train = df.index[~df['is_val']].tolist()
valid = df.index[df['is_val']].tolist()
return train, valid
# `get_dls` creates dataloaders with RandomResizedCrop of the specified size
# and also with all the default augmentations
def get_dls(size=224):
cassava = DataBlock(
blocks = (ImageBlock, CategoryBlock),
get_x=get_x,
get_y=get_y,
splitter=splitter,
item_tfms=[RandomResizedCrop(size, min_scale=0.7)],
batch_tfms=[*aug_transforms()]
)
dls = cassava.dataloaders(df, bs=64)
return dlsWe create a ResNet-50 with pretrained weights and then train the entire network at a resolution of 224x224.
dls = get_dls()
learn = cnn_learner(dls, resnet50, metrics=accuracy)
learn.fine_tune(5)| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 1.067555 | 0.806518 | 0.727506 | 02:55 |
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.675441 | 0.725409 | 0.757887 | 03:44 |
| 1 | 0.543039 | 0.556987 | 0.820986 | 03:44 |
| 2 | 0.463506 | 0.510089 | 0.833606 | 03:44 |
| 3 | 0.340905 | 0.478553 | 0.843188 | 03:44 |
| 4 | 0.276000 | 0.470489 | 0.849965 | 03:44 |
We then freeze the earlier layers of the model and fine-tune the last layer with a higher resolution.
new_dls = get_dls(size=280)
learn.dls = new_dls
learn.freeze()
learn.fit(5)| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.319706 | 0.466751 | 0.856509 | 04:38 |
| 1 | 0.298980 | 0.547480 | 0.825193 | 04:34 |
| 2 | 0.286727 | 0.461916 | 0.858378 | 04:34 |
| 3 | 0.280145 | 0.508987 | 0.841785 | 04:34 |
| 4 | 0.268317 | 0.517633 | 0.842253 | 04:34 |
This gives us a peak accuracy of 85.84%!
The process is very similar to progressive resizing. The difference is that with progressive resizing, we train the entire network with larger images. But with FixRes, we are just fine-tuning the last layers of the network with larger images.
Conclusion
Standard data augmentation techniques change the apparent size of objects during training.
As a result, the model sees objects of different scale during training and testing. This is a problem because CNNs are not scale invariant.
This can be remedied by training with smaller images, or testing with larger images.
However, using images of different size at train time and test time negatively affects the classifier layers of the CNN.
To address this, we fine tune the last few layers of the model, including the batch-norm layer preceding the global pooling layer at the higher resolution being used at test time.
This approach can be used when training a model from scratch and also with transfer learning.
Acknowledgements
- Aman Arora for the amazing Fastbook reading group sessions where he introduced this paper to us, for encouraging us to start reading research papers and for motivating us to actively write about what we learn in our deep learning journey.
- Sanyam Bhutani for running the PyTorch book reading group sessions and encouraging us to have a bias towards action - writing code and trying things out instead of just reading. The PyTorch code I managed to write in this blog post is a result of the awesome study group he's running.
- Morgan McGuire for making his amazing fastgarden of FixRes experiments available on GitHub which made it very easy for me to understand how to use FixRes with fastai.